I've been working on genetics and evolution for my entire research career. Whilst most methodology I develop has wider application, I have always put in extra care to ensure that methodology for genetics takes into account the specialities specific to this data.
FineSTRUCTURE
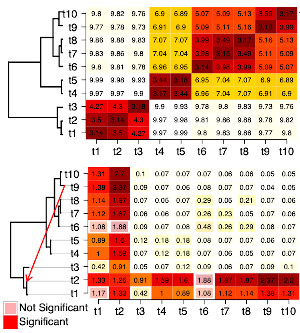
FineSTRUCTURE is a whole pipeline that deserves, and has, its own FineSTRUCTURE website. It is a sophisticated modelling tool that uses Data Science ideas - of identifying computational questions that can be answered, and wrapping them up in a statistical modelling framework that means something. The FineSTRUCTURE algorithm was developed in 2012 but is still the most accurate way to estimate fine-scale variations in Ancestry.
High Profile applications include:

Genomic Architecture
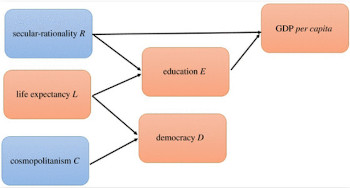
Genomic Architecture is a description of how the whole genome comes together to construct a complex trait, such as height, education, body-mass-index, and so on. The relationship is extremely rich and of course depends on all sorts of variables such as cultural practice, personal circumstances, and so on.
My work focusses on population structure and how this has confounded previous analyses, as well as methods to limit this confounding. Key outputs include:
badMIXTURE
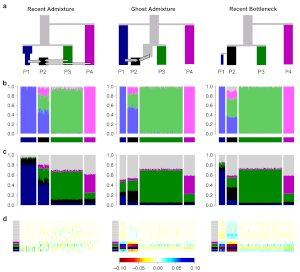
badMIXTURE is an important tool to compare the output of some claimed mixture to another dataset that may or may not show this mixture. It works by comparing mixtures generated using genome-wide unlinked markers (with tools such as ADMIXTURE) to results from FineSTRUCTURE above. These are theoretically the same if the mixture is true.
badMIXTURE is published under the title A tutorial on how not to over-interpret STRUCTURE and ADMIXTURE bar plots. As always, it turned out to be important to understand the details of what the models were doing in order to make the software appropriate for the complexity that is genetic data.
badMIXTURE is the spiritual precursor to CLARITY, which expands this idea to a much wider range of models.